Documentação
Apresentação
Este projeto apresenta uma solução completa que inclui uma API em Python que tem endpoints que servem para obter os dados referentes aos klines/candlesticks/velas dos preços do BitCoin conforme fornecido pela Binance, criar um modelo de regressão para predizer klines, modelo de classificação para dizer se a previsão é de subida ou descida e trazer informações para gerar gráficos para melhorar acompanhar os resultados. Existe um endpoint que serve para popular inicialmente o banco de dados com informações dos ultimos 90 dias, caso não haja dados suficientes recentes, executado uma única vez e endpoint para alimentar o banco de dados com o valor atual, sob demanda. A lista completa de endpoints com suas funcionalidades estão disponíveis no item do menu da documentação "Endpoints da API".
Além da API, tem um projeto em Asp .NET 9.0 MVC que além de servir esse site, tem jobs configurados através do Quartz.NET para fazer requisições para os endpoints da API para alimentar com dados atualizados o banco de dados em PostgreSQL a cada 5 minutos. O treinamento do modelo é orquestrado pelo Quartz (Opção C): um job diário executa POST /train e POST /series/rebuild, e outro job faz checagem de drift via MAPE(rolling) em futures para decidir se treina antes do diário. Tanto a API em Python, quanto a aplicação do site e os jobs em ASP .NET, quanto o PostgreSQL e o Adminer para consultar os dados gravados estão todos dentro de containers Docker, agrupados com Docker Compose e hospedados em minha VPS, gerenciados com Portainer e usando o Traefik para proxy reverso.
A solução da API está disponível no GitHub do desenvolvedor: Bitcoin LSTM. Em produção, os hosts/paths ficam configuráveis via variáveis de ambiente (ex.: SITE_HOST, API_HOST, API_PATH_PREFIX).
O que o modelo faz (em alto nível)
- O modelo aprende a prever o próximo candle (t→t+1, horizonte de 5 minutos), usando um histórico recente (sequência) como entrada.
- Saídas:
- Regressão:
open_next,high_next,low_next,close_next,amp_next - Classificação: direção do próximo candle (probabilidade de alta/baixa)
- Regressão:
Limitações (importante para interpretação)
- Horizonte curto: prever o próximo candle não implica previsão de longo prazo.
- Sinal fraco x ruído: boa métrica em validação pode não se manter em produção.
- Custos e execução: o projeto não modela taxa/spread/slippage, então não conclui “compra/venda” automaticamente.
1. Introdução
Através dessa documentação voce será apresentado ao código da API, configurações dos jobs do Quartz.NET, tabelas do banco de dados PostgreSQL e a arquitetura do projeto.
2. Motivação
O desenvolvimento dessa solução visa atender ao Tech Challenge Fase 04 do curso de Machine Learning Engineering da FIAP.
3. Requisitos
- Coleta de Dados: utilize um dataset de preços históricos de ações, como o Yahoo Finance ou qualquer outro dataset financeiro disponível
- Construa um modelo de deep learning utilizando LSTM para capturar padrões temporais nos dados de preços das ações.
- Treinamento: treine o modelo utilizando uma parte dos dados e ajuste os hiperparâmetros para otimizar o desempenho.
- Avaliação: avalie o modelo utilizando dados de validação e utilize métricas como MAE (Mean Absolute Error), RMSE (Root Mean Square Error), MAPE (Erro Percentual Absoluto Médio) ou outra métrica apropriada para medir a precisão das previsões.
- Salvar o Modelo: após atingir um desempenho satisfatório, salve o modelo treinado em um formato que possa ser utilizado para inferência.
- Criação da API: desenvolva uma API RESTful utilizando Flask ou FastAPI para servir o modelo. A API deve permitir que o usuário forneça dados históricos de preços e receba previsões dos preços futuros.
- Monitoramento: configure ferramentas de monitoramento para rastrear a performance do modelo em produção, incluindo tempo de resposta e utilização de recursos.
Entregáveis:
- Código-fonte do modelo LSTM em repositório GIT documentação.
- Scripts ou contêineres Docker para deploy da API.
- Link para a API em produção
- Vídeo mostrando e explicando todo o funcionamento da API
4. Arquitetura Geral
A arquitetura geral da solução é apresentada na imagem a seguir. Ela contempla o fluxo de dados desde a requisição à API da Binance, gravação no banco de dados PostgreSQL, treinamento do modelo de regressão e classificação e disponibilização dos dados em gráficos no site hospedado.
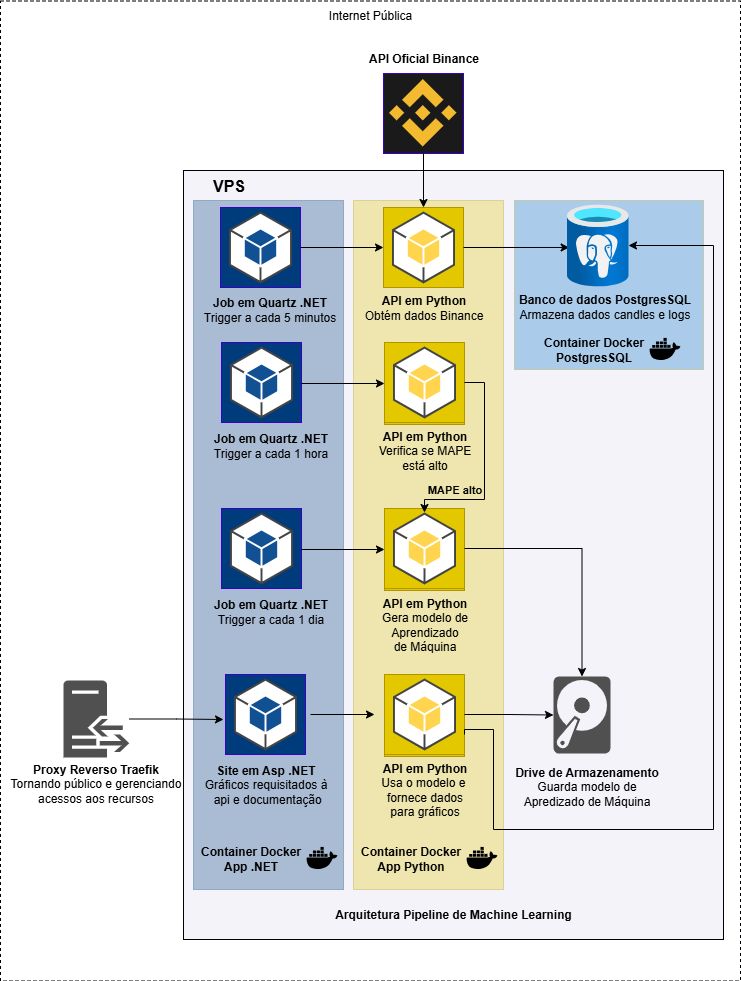
5. Solução Desenvolvida
Visão geral em dois blocos: site (ASP.NET Core 9.0) e API (Python/FastAPI), ambos em containers Docker com Postgres para persistência.
5.1 Site (ASP.NET Core 9.0 MVC)
- UI e documentação: página de Docs (Markdown) e Swagger da API Python embutido em uma view.
- Jobs com Quartz.NET:
- Ingest (a cada 5 min): chama
/ingestna API Python para buscar candles recentes (Binance) e persistir no Postgres. - TrainDaily (1x ao dia): chama
/trainpara treinar o modelo e/series/rebuildpara materializar a série. - TrainDrift (periodicamente): calcula MAPE(rolling) em
futurese dispara/train+/series/rebuildapenas quando necessário. - Backfill (uma vez no startup): chama
/init/backfillpara histórico inicial.
- Ingest (a cada 5 min): chama
- Charts: consome
/series,/metrics,/futurespara exibir velas reais × previstas, erro (%), série prospectiva e métricas direcionais.
5.2 API (Python + FastAPI)
- Ingestão (
/ingest): baixa klines (OHLCV) da Binance (janela recente), normaliza e upserta embtc_candles(Postgres). Atualiza também a série prospectivafuturespara o último timestamp válido. - Treinamento (
/train): constrói features (ret, acc, amp, vol_rel), monta sequências, aplica split temporal (80/20) e treina uma rede LSTM (TensorFlow/Keras) multi-tarefa (regressão OHLC/amp do t+1 + classificação direcional). Salva artefatos no volume e registra métricas (MAE, RMSE, MAPE, SMAPE) emjob_logs. - Séries (
/series): retorna pontos com candle real, previsão do próximo candle (t→t+1), classificação e erros relativos ao próximo candle para alimentar os gráficos. - Métricas (
/metrics): expõe as métricas do último treino e o início do período de validação (para sombreamento nos gráficos). - Futuros (
/futures,/futures/update): mantém série prospectiva (pred_close × real_close × err_close) alinhada por tempo, usada para avaliação out-of-sample contínua.
5.3 Banco de dados (Postgres)
- Tabelas principais:
btc_candles(time, open, high, low, close, volume): candles normalizados da Binance.job_logs(id, job_name, status, message, started_at, finished_at): logs de execuções (ingest/train/backfill) e mensagens com métricas.futures(time, pred_close, real_close, err_close): previsões prospectivas comparadas ao realizado.
Tem um link para o Adminer (que também está rodando em container Docker) está disponível no menu principal para conferir os dados salvos no banco de dados PostgreSQL e os schemas das tabelas. Um usuário de teste e apenas com permissões de leitura foi criado para fins acadêmicos:
Sistema: PostgreSQL Usuário: teste Senha: teste Banco de dados: btcdb
Todos os serviços (site, API, Postgres e Adminer) sobem via Docker Compose, compartilhando rede e volumes (modelos e dados persistidos entre reinícios).